Zusammenhang gesucht
| updated: | 2011-01-17 |
|---|---|
| created: | 2010-11-27 |
Motivation
Konversation braucht zwar immer jemanden (oder etwas), der sie einleitet. Aber sobald dieser Schritt geschafft ist, lebt sie vor allem von Antworten, also davon, dass sich jemand mit einem neuen Gedanken auf das vorher Gesagte bezieht. Wer später dazukommt, der hat das Problem, dass er zunächst – im wahrsten Sinne des Wortes – nicht mitreden kann, weil der Kontext fehlt.
In der schriftlichen Kommunikation fällt dieser Nachteil weg. Jeder kann alles zu jedem Zeitpunkt noch einmal lesen und dann gegebenenfalls später einsteigen. Dadurch ist es möglich, dass sich verzweigte Konversationen mit baumartigen Strukturen entwickeln.
Was aber tun, wenn zwar das Gesagte, aber nicht die Struktur desssen erhalten geblieben ist? Wer hat sich auf wen bezogen? Wo ist die Antwort auf X? Oder wie weit ist ein Konversationsstrang inzwischen verzweigt? Womit fing alles an? Alle diese Fragen können helfen sich in einer großen Menge von Nachrichten besser zurechtzufinden. Und sie sind auch die Motivation für diesen Artikel. Oder besser: Den Inhalt dieses Artikels.
Praktisch motiviert ist er durch eine von 1997–1999 aktive Mailingliste, von der nur noch die Archive erhalten geblieben sind. Allerdings, und hier beginnt das Problem, ohne Informationen zur Struktur: Die üblichen „In-Reply-To“- oder „References“-Header fehlten in Gänze. Dadurch wurde aus der baumartigen Konversationsstruktur eine einfache Liste; chronologisch sortiert nach Datum und Betreff. Und die liest sich offensichtlich nur sehr schlecht.
Da das Archiv knapp 15000 Nachrichten groß ist, war das händische Sortieren keine Option. Herausgekommen ist am Ende der im Folgenden beschriebene Algorithmus, der, und hier greife ich ein wenig vor, das Chaos zumindestens ein wenig beseitigt hat. Das Ergebnis ist übrigens im Ocean Girl Archive zu finden.
Levenshtein-Distanz
Die Levenshtein-Distanz ist definiert als kleinste Anzahl an Operationen, die nötig sind, um einen String A in einen String B zu transformieren. Als Operationen kommen Ersetzen, Einfügen und Löschen infrage.
In [Navorro2001] ist ein recht einfacher Dynamic Programming Algorithmus beschrieben, der diese Distanz in \(O(nm)\) berechnet. Neben der Edit Distance fällt auch, mehr oder weniger als Nebenprodukt, eine Liste von Einzeloperationen an, die für die Transformation notwendig sind. Diese wird im folgenden Algorithmus benutzt – die Levenshtein-Distanz an sich dagegen wird nicht gebraucht.
Der Algorithmus
Alle hier beschriebenen Vorschriften beziehen sich auf den Spezialfall E-Mail, sind aber im Prinzip für alle schriftlichen Konversationen geeignet, in denen Zitate besonders gekennzeichnet werden. Ein Beispiel hierfür könnten Posts in BulletinBoards sein, die mit BB-Tags wie „[quote]“ gekennzeichnet sind. Die Implementierung des Algorithmus ist dann entsprechend anzupassen.
Zunächst müssen alle Nachrichten in nach Datum sortierter Form vorliegen. Im weiteren Verlauf wird der Grund dafür ersichtlich werden.
Weiterhin werden verschiedene „normalisierte“ Varianten einer Nachricht benötigt:
Zum einen eine, in der die Nachricht in Kleinbuchstaben umgewandelt wird, alle aufeinanderfolgenden Leerzeichen, Tabs und ähnliche Zeichen durch ein einzelnes Leerzeichen ersetzt werden. Außerdem müssen alle > am Zeilenanfang entfernt werden, da das Größer-Als-Zeichen in der Regel in Zitaten verwendet wird.
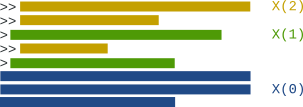
Und zum anderen eine, in der alle Zitatebenen, also mit > eingerückte Teile, voneinander getrennt und wie in 1. beschrieben normalisiert wurden. Die einzelnen Zitatebenen werden in diesem Dokument mit X(n), wobei X die Nachricht und n die Ebene ist. X(0) entspricht der von Zitaten befreiten Nachricht.
Um die Laufzeit des Algorithmus klein zu halten, werden nun alle Nachrichten nach ihrem Betreff gruppiert. Indikatoren für eine Antwort, wie zum Beispiel „Re:“ oder das im Deutschen gebräuchliche „Aw:“ werden dafür ebenso entfernt, wie auch eckige Klammern und Vorangestellte „Fwd:“.
Da es bei sehr großen Archiven durchaus möglich ist, dass verschiedene Threads denselben Betreff nutzen, wird noch ein „Thread-Breaker“ eingeführt, der einen neuen Thread beginnt, sobald eine zeitlich gesehen neuere Nachricht nicht mehr wie eine Antwort aussieht, also kein „Re:“ oder ähnliches im Betreff enthält. Möglich wäre hier auch eine Trennung der Threads, wenn Antworten zeitlich sehr weit auseinanderliegen.
Die bisherigen Schritte könnte man unter „Preprocessing“, also Vorverarbeitung der Daten, verbuchen – nun folgt die eigentliche Arbeit, die sich in der Praxis als sehr rechenaufwändig herausstellen wird:
Für jedes Paar (A,B) von Nachrichten eines Threads werden, wie oben beschrieben, die Anzahl der benötigten Einzeloperationen für die Transformation der Nachricht A in die Nachricht B berechnet.
Zunächst wird auf vollständige Zitate geprüft: Dabei sollte es einleuchtend sein, dass B genau dann A enthält (B also A komplett zitiert), wenn es weder Ersetzungen noch Löschungen, aber mehr als Null Einfügungen gibt und die Länge von B größer ist als die von A.
Wenn der Test auf ein vollständiges Zitat fehlschlägt, dann bleibt noch die Möglichkeit die Nachricht B auf ein partielles Zitat zu überprüfen. Das funktioniert allerdings nur, wenn die Nachricht im 2. Normalisierungsschritt tatsächlich in Zitate 1. bis n-ter Ordnung aufgeteilt werden konnte, also in der Regel nur dann, wenn sich die Kommunikationsteilnehmer an gewisse Konventionen (Einrücken von Zitaten mit >) gehalten haben.
Auch hier sollte wieder einleuchtend sein, dass zum Beispiel die Zitatebene 1 der Nachricht B (auch: B(1)) genau dann keine Einfügungen und Ersetzungen, aber mehr oder genau Null Löschungen erfährt, wenn es sich um ein Zitat der Nachricht A handelt. Bei Bedarf kann man auch weitere Ebenen überprüfen, um zu genaueren Ergebnissen zu gelangen. Zum praktischen Nutzen kann aber an dieser Stelle keine Aussage gemacht werden.
Es sollte noch darauf hingewiesen werden, dass man sich Arbeit sparen kann, wenn man, wie oben erwähnt, die Nachrichten nach ihrem Erstellungsdatum sortiert, denn eine neuere Nachricht kann niemals von einer älteren zitiert werden (weder in Gänze, noch teilweise), sofern die Datumsangaben korrekt sind.
Praxistest
Dass der oben beschriebene Ansatz tatsächlich erstaunlich gut funktioniert, sieht man an folgenden Beispielen. Dafür wurden mittels der Gmane-Export-API jeweils die neusten etwa 1000 Nachrichten der entsprechenden Liste exportiert und mit einer Implementierung des oben beschriebenen Algorithmus bearbeitet. Die verwendeten Mailinglisten wurden – mehr oder weniger – zufällig ausgewählt.
Da bei den exportierten Nachrichten Informationen zu Threads vorhanden sind, ist es sehr leicht möglich die Übereinstimmungen zwischen den „In-Reply-To“-Headern vor und nach dem Ausführen des Algorithmus zu zählen. Die folgende Tabelle zeigt die Ergebnisse:
| Mailingliste | Nachrichten | Übereinstimmung |
|---|---|---|
| linux.gentoo.devel | 1085 | 90,22% |
| os.freebsd.current | 1099 | 85,34% |
| editors.vim | 1081 | 84,09% |
| comp.php.general | 1058 | 83,74% |
| linux.busybox | 1052 | 82,60% |
| os.cygwin | 1102 | 82,03% |
| recreation.canals | 1065 | 78,97% |
| org.user-groups.mlug | 1101 | 77,66% |
| law.cryptography.uk | 1013 | 76,80% |
| network.end2end | 1102 | 71,96% |
| ietf.dkim | 1342 | 69,15% |
| games.spielfrieks | 1038 | 66,18% |
| science.dinosaurs.general | 1126 | 57,73% |
| comp.db.couchdb.devel | 1440 | 37,92% |
Es lohnt sich das Ergebnis von couchdb-devel genauer zu beleuchten. Wie man unschwer erkennen kann, ist es nur möglich unter 40% der Nachrichten wieder korrekt einzuordnen. Schaut man sich die Mailingliste einmal genauer an, so fällt auf, dass sie viele automatisch generierte Nachrichten mit immer wiederkehrenden Texten enthält. Entfernt man diese Nachrichten, so kommt man mit nunmehr 456 Nachrichten auf 71,93% Übereinstimmung, was etwa im unteren Mittelfeld liegt.
An dieser Stelle sei nochmal darauf hingewiesen, dass die angegebene prozentuale Übereinstimmung nur eine Aussage darüber trifft wieviele Nachrichten wieder an exakt derselben Stelle einsortiert wurden. Die Zahlen beachten weder die Nachrichten, die „mehr oder weniger richtig“, also zum Beispiel dem korrekten Thread, zugeordnet wurden noch wurden Nachrichten aus der Statistik entfernt, die keine Zitate enthalten und somit nur mit einem gewissen Sprachverständnis zugeordnet werden können.
Verbesserungen
- Im Moment ist die Berechnung der Einzeloperationen der Flaschenhals des Algorithmus. Mit einer schnelleren Implementierung oder einem schnelleren Ansatz könnte also sehr viel Zeit gespart werden.
- Der vorgestellte Algorithmus lässt sich in der Praxis in weiten Teilen ganz gut parallelisieren, sodass man auch an dieser Stelle nochmal Zeit sparen kann.
Quelltext
Eine Implementierung des oben beschriebenen Algorithmus ist hier als Python-Skript (2010-11-29) verfügbar. Es enthält noch ein paar mehr Funktionen, ist aber dafür nicht besonders sauber programmiert. Zum Ausführen wird die Bibliothek pylevenshtein benötigt.
Außerdem sind die verwendeten Mailinglistenauszüge (22MB) verfügbar.
Literatur
| [Navorro2001] | Navarro, Gonzalo. 2001. A Guided Tour to Approximate String Matching. ACM Computing Surveys, Vol. 33, No. 1, pp. 31–88. |