Barriers
In multi-threaded computing only a few basic synchronization methods like mutex locks and barriers exist. They can be used to build larger, more complex synchronization schemes.
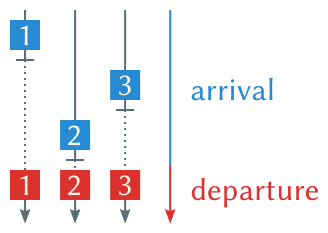
Barriers can used to wait for all results of a parallel computation to possibly merge or serialize them in the next step. They are usually split into two steps: The arrival or trapping step puts threads arriving at the barrier into a wait state or busy loop. They cannot continue execution. Once the other threads have been trapped by the barrier too the departure or release step is entered which releases all threads from their busy loop at once. Now they can continue past the barrier.
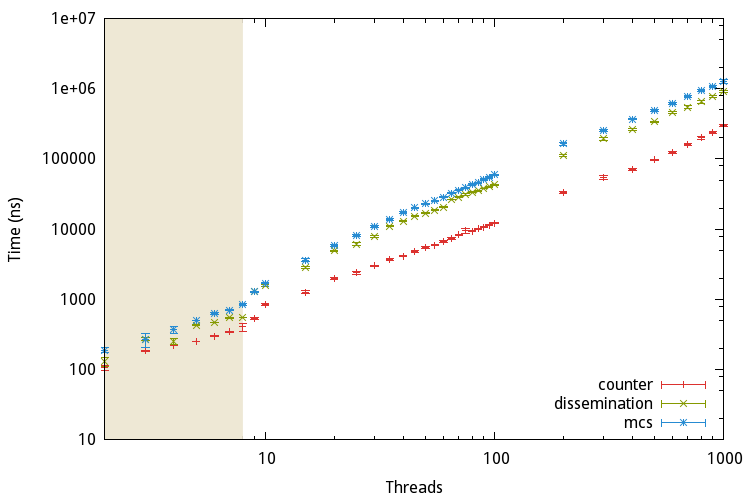
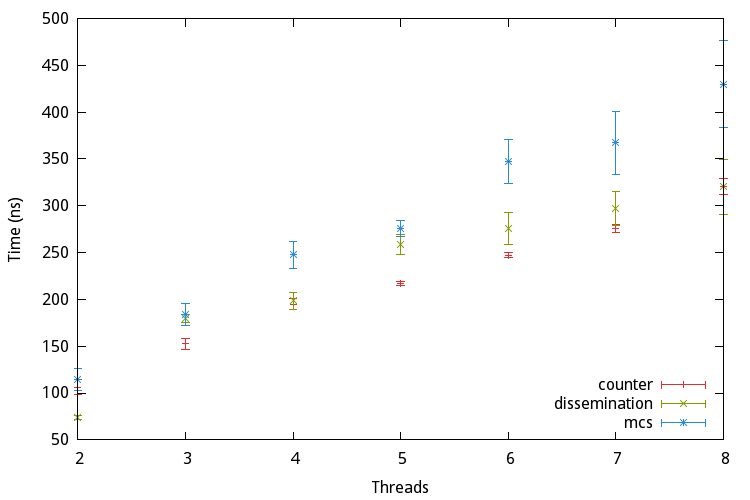
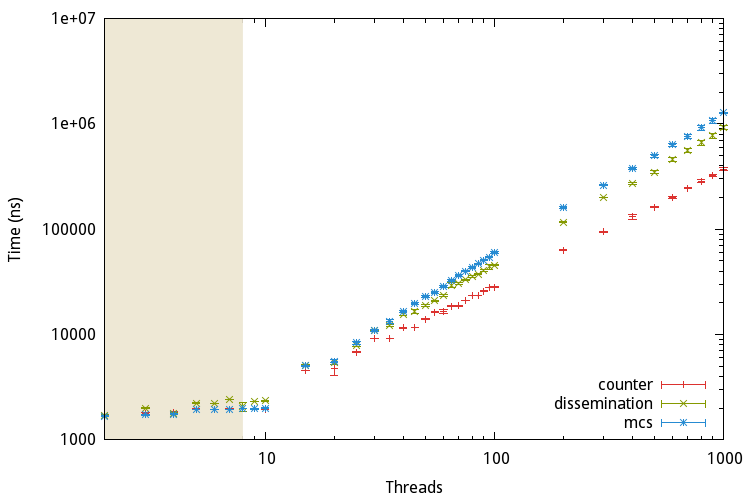
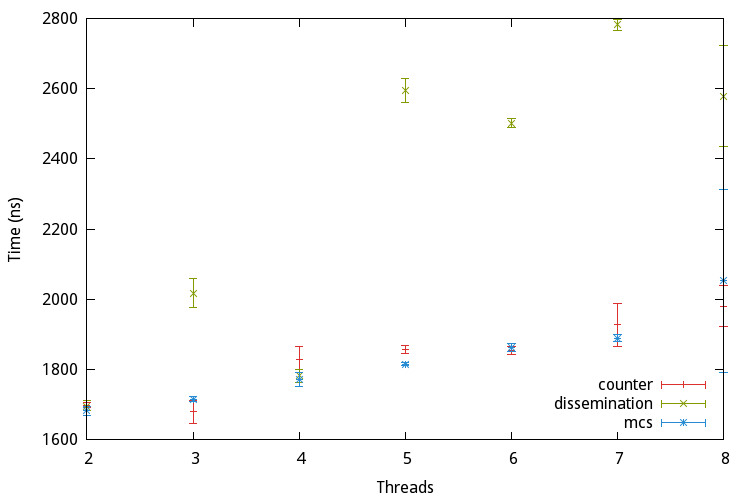
For this purpose different algorithms with different strategies have been proposed. They can be arranged into three categories: The linear barrier, the tree barrier and the butterfly barrier. The following sections present one algorithm for every category.
Linear barrier
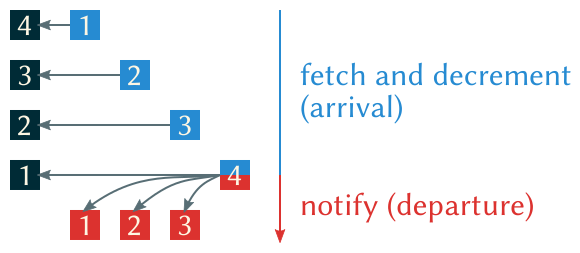
An example of a linear barrier is the centralized, counter-based algorithm. Basically there exists one shared counter initially containing the number of threads. Once a thread arrives at the barrier it is atomically decremented and the thread waits for a global release flag to change state. If the counter’s value reaches zero this flag is updated to release all waiting threads. Due to its simplicity it can be implemented with a few lines of C code:
localsense = !localsense; if (__sync_fetch_and_sub (&count, 1) == 1) { count = THREADS_COUNT; globalsense = localsense; } else { while (globalsense != localsense); }
There are two flags shared by all threads, count and globalsense and one local flag for each thread, localsense. Upon entering the barrier a thread inverts its local sense flag (sense inversion1) and atomically fetches and decrements the global counter with __sync_fetch_and_sub, a built-in function of gcc. The last thread arriving at the barrier resets the counter and assigns its localsense to the globalsense variable. The other threads have been polling this variable in a while-loop and are now released.
| [1] | also known as sense reversal or sense switching |
Tree barrier
As the name implies tree barriers arrange the threads in a tree. One example for this kind of barrier is the MCS barrier, named after the authors John M. Mellor-Crummey and Michael L. Scott.
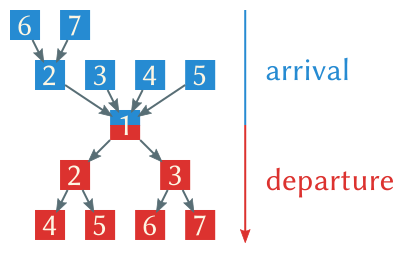
Every node in the arrival tree has four children, which notify their parent as soon as they arrived at the barrier (fan-in is four). Once the root node, usually the thread with id 1, and all of its children have arrived too the release phase is entered. This time every parent notifies its two children (fan-out is two), thus propagating the departure signal down the tree, as shown in the figure above.
typedef struct { uint8_t parentsense; uint8_t *parent; uint8_t *children[2]; union { uint8_t single[4]; uint32_t all; } havechild; union { uint8_t single[4]; uint32_t all; } childnotready; uint8_t sense; uint8_t dummy; unsigned int id; } thread_t;
Every thread maintains pointers to flags in their parent (arrival) and two children (departure). As shown below parent is initialized to the appropriate byte in the parent’s childnotready and children points to the child’s parentsense. havechild enables us to use thread counts not divisible by four, the fan-in.
/* for all threads from 0…P-1 */ t = &thread[i]; for (size_t j = 0; j < 4; j++) { t->havechild.single[j] = (4*i+j < (P-1)) ? true : false; debug ("havechild[%u]=%i\n", j, t->havechild.single[j]); } t->parent = (i != 0) ? &thread[(i-1)/4].childnotready.single[(i-1)%4] : &t->dummy; t->children[0] = (2*i+1 < P) ? &thread[2*i+1].parentsense : &t->dummy; t->children[1] = (2*i+2 < P) ? &thread[2*i+2].parentsense : &t->dummy; t->childnotready.all = t->havechild.all; t->parentsense = 0x0; t->sense = 0x1; t->dummy = 0x0; t->id = i;
Above the initialization phase for the MCS barrier is shown. dummy is a small optimization to avoid compare operations in the barrier function, which looks like this:
t = &thread[i]; while (t->childnotready.all != 0x0); t->childnotready.all = t->havechild.all; *t->parent = 0x0; if (t->id != 0) { while (t->parentsense != t->sense); } *t->children[0] = t->sense; *t->children[1] = t->sense; t->sense = !t->sense;
First each thread waits for its children to arrive at the barrier. Then childnotready is reset for the next time the barrier is entered and the thread’s parent is notified. Note that parent points to the inverse-logic childnotready and is therefore set to 0. If the current thread is not the root of either (arrival or departure) tree each thread waits for the departure signal, which is then forwarded to its children. This implementation uses sense-inversion too.
Butterfly barrier
Finally we take a look at the dissemination barrier proposed by Hensgen, Finkel, and Manber, which belongs to the category butterfly barrier.
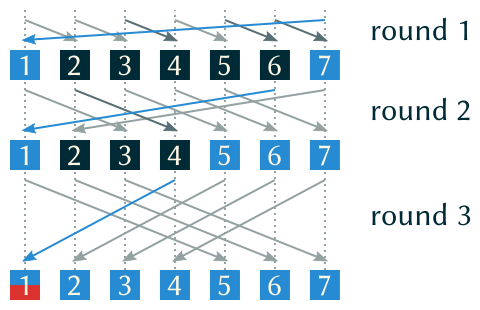
As we can see above the barrier is round-based and every thread has its own view of all the other threads involved in the synchronization. The image highlights the important bits for thread 1. Let’s imagine we are this thread now.
Initially we obviously know that we arrived at the barrier. In round one thread 7 sent us a notification and therefore arrived at the barrier too.
Now look at round two: Thread 6 sent us a notification. We also know that the only way for thread 6 to send us a notification in round two is to receive a notification from thread 5 in round one. Thus the latter must have arrived at the barrier too.
We can move on to round three where thread 4 sent us a notification. Again, we know that thread 4 received a notification from thread 3 in round one and from thread 2 in round two. That means both of them have arrived at the barrier.
This scheme works the same way for every thread, not just the first one. With this high-level overview we can go ahead and implement the barrier algorithm:
typedef struct { bool mine; bool *partner; } flags_t; typedef struct { flags_t flags[2][WORKER_LOG2]; bool sense; unsigned int parity; } thread_t;
Every thread has flags for every round and every parity (which is either 0 or 1). The flags consist of mine, which is updated by a different thread and partner, which points to a different thread’s mine. parity provides race-free reuse of the barrier by using different flags for two consecutive barrier function calls.
/* for all threads from 0…P-1 */ t = &thread[i]; t->sense = true; for (size_t r = 0; r < 2; r++) { for (size_t k = 0; k < log2 (P); k++) { unsigned int j = (i+pow2 (k)) % P; t->flags[r][k].partner = &thread[j].flags[r][k].mine; } }
The initialization code assigns each thread a partner for every round.
t = &thread[i]; for (unsigned int i = 0; i < log2 (P); i++) { flags_t * const flags = &t->flags[t->parity][i]; *flags->partner = t->sense; while (flags->mine != t->sense); } if (t->parity == 1) { t->sense = !t->sense; } t->parity ^= 0x1;
As described above for every round i the partner’s flag mine, which parent points to is set to sense. Then the thread waits for its partner to update mine. Again sense-inversion is used.